
Large language models (LLMs) have gained significant popularity in various fields due to their ability to generate and manipulate text in multiple languages. While these models are highly advanced and can produce texts that closely resemble human writing, they have been found to exhibit a phenomenon called hallucinations, where they generate inaccurate or nonsensical responses. Researchers at DeepMind have recently proposed a new approach to address this issue and improve the reliability of LLMs.
Hallucinations in LLMs pose a significant challenge as they can lead to the generation of incorrect or inappropriate responses. These hallucinations can undermine the credibility of the model and hinder its usefulness in real-world applications. The ability to identify instances where the model is likely to hallucinate and refrain from providing a response is crucial to ensure the accuracy and trustworthiness of the information generated by LLMs.
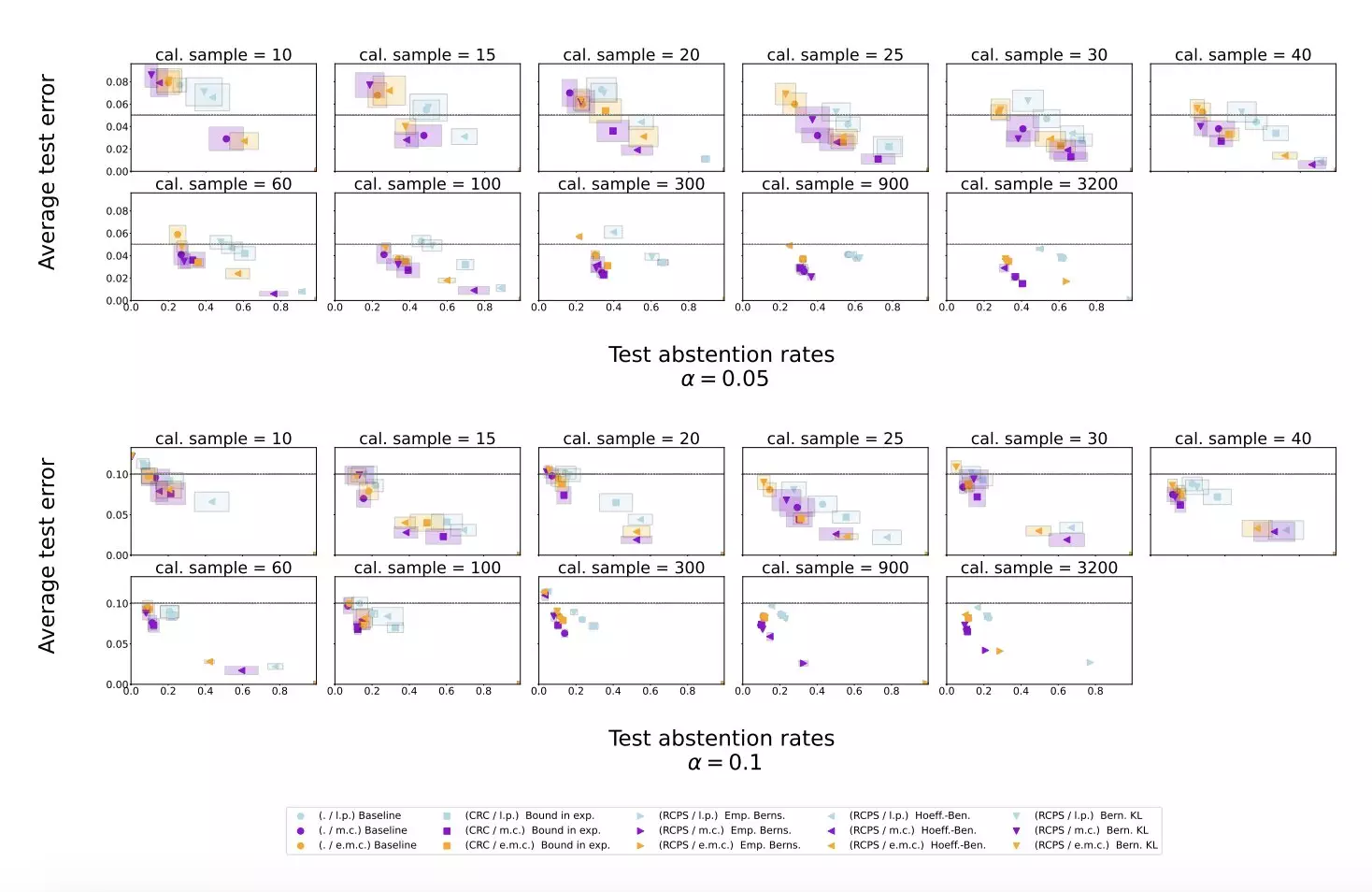
The team at DeepMind has developed a novel procedure to mitigate LLM hallucinations by allowing the model to evaluate its own potential responses. By comparing the similarity between different sampled responses for a given query, the model can determine the reliability of its answers and refrain from responding in cases where the responses are likely to be inaccurate or nonsensical. This self-evaluation process, combined with conformal prediction techniques, provides a rigorous method for identifying and preventing LLM hallucinations.
The researchers conducted experiments using publicly available datasets and applied their proposed method to an LLM called Gemini Pro. The results showed that the conformal abstention method effectively reduced the hallucination rate on various question answering datasets, while maintaining a reasonable abstention rate. By incorporating a similarity scoring procedure and calibration based on conformal prediction, the researchers were able to improve the reliability of LLMs and outperform baseline scoring procedures.
Implications and Future Research
The findings of this study have significant implications for the development of LLMs and their widespread use in various industries. By addressing the issue of hallucinations and improving the reliability of these models, researchers can enhance the trustworthiness of the information generated by LLMs and prevent them from producing inaccurate or nonsensical responses. Future research in this area will focus on further refining the proposed method and developing similar approaches to enhance the performance of LLMs.
The research conducted by DeepMind represents a significant step towards addressing the challenges associated with LLM hallucinations. By implementing self-evaluation techniques and conformal prediction methods, researchers have developed a promising approach to improving the reliability of LLMs and preventing them from generating inaccurate responses. These efforts will contribute to the advancement of LLM technology and enable professionals worldwide to leverage these models with confidence.
Leave a Reply