
Nvidia has taken a monumental leap in the realm of AI infrastructure with its latest open-source release of the KAI Scheduler, a cutting-edge component of the Run:ai platform. Announced recently, this initiative allows developers and enterprises alike to tap into a solution that simplifies and enhances GPU scheduling in Kubernetes environments. With the KAI Scheduler now available under the Apache 2.0 license, this move aligns perfectly with Nvidia’s broader commitment to foster collaborative innovation and drive advancements in both open-source and enterprise AI frameworks.
Open sourcing elements like the KAI Scheduler is not merely a business strategy; it embodies a paradigm shift in how companies can harness the power of AI. By encouraging community contributions and feedback, Nvidia sets the groundwork for a vibrant ecosystem where collaboration reigns, ultimately pushing technological boundaries further. As competitive pressures mount, such initiatives will empower IT and ML teams to be more agile and responsive to dynamic workloads, enabling them to harness AI’s full potential.
The Challenge of GPU Resource Management
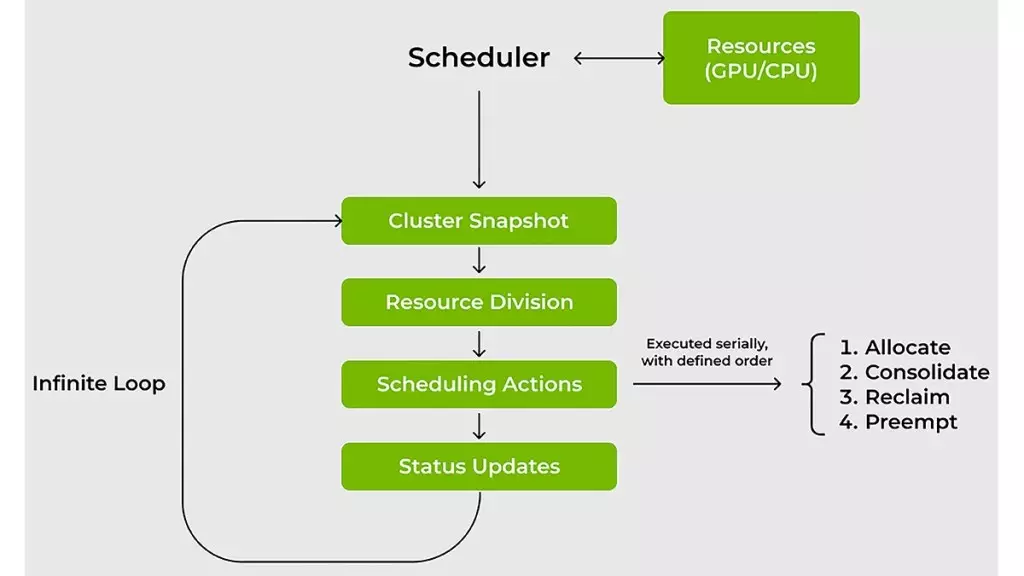
Managing AI workloads effectively is akin to navigating a labyrinth filled with pitfalls and challenges, especially when utilizing GPUs and CPUs. Traditional resource schedulers encounter significant limitations, especially as they handle fluctuating demands from AI tasks. For instance, a typical workflow might necessitate a solitary GPU for data exploration, but that requirement could surge into the need for multiple GPUs during intense training sessions or iterative experiments. Most conventional schedulers fall short in accommodating such volatility, leading to inefficient resource usage and increased wait times.
The KAI Scheduler directly confronts these challenges head-on. It employs a dynamic, real-time approach to managing workloads, revisiting and recalibrating resource allocations based on fluctuating demands. The scheduler’s capability to continuously adjust quotas and fair-share values ensures that users receive immediate access to computational power without the laborious wait traditionally imposed by static scheduling. This is a significant leap for machine learning (ML) engineers, as reduced wait times directly translate to increased productivity and faster iterations in the development process.
Empowering ML Engineers Through Innovative Techniques
Speed is the essence of success in the fast-paced world of machine learning, and the KAI Scheduler recognizes this vital need. By integrating techniques such as gang scheduling, GPU sharing, and a sophisticated hierarchical queuing system, it ensures that submissions of job batches occur seamlessly. Engineers can submit multiple jobs, secure in the knowledge that tasks will launch promptly as soon as resources align with the established priorities. This not only alleviates the pressure on administrators but also allows ML teams to focus on what they do best—creating and innovating.
Moreover, the scheduler employs dual effective strategies to optimize resource utilization: bin-packing and spreading. Bin-packing effectively addresses resource fragmentation by maximizing compute usage, whereas spreading ensures a balanced distribution of workloads across various nodes. This dual-pronged approach solves the persistent issues of underutilized resources, a common plight in shared cluster environments. It’s not uncommon for researchers to hoard GPUs unnecessarily, a mindset which only exacerbates efficiency problems. By enforcing resource guarantees, the KAI Scheduler promotes a culture of accountability among teams, optimizing cluster efficiency and preventing resource hogging.
Simplifying Complex Workflows for Enhanced Collaboration
In an increasingly interconnected world, the integration of various AI frameworks poses yet another challenge for teams striving for efficiency. Tying workloads together with tools like Kubeflow, Ray, and Argo often necessitates a hefty amount of manual configuration, significantly delaying the development process. The KAI Scheduler addresses this complex web by introducing a built-in podgrouper, allowing the seamless integration of these frameworks.
The result? Reduced configuration complexity and a significant speed-up in the development lifecycle. This is more than just a technical advancement; it’s a shift in mindset, where enabling collaboration and innovation supersedes the burdens of manual overwriting. By simplifying the connection between workloads and AI frameworks, Nvidia pushes the frontiers of efficiency and creativity, paving the way for groundbreaking advancements in AI.
Nvidia’s KAI Scheduler represents a watershed moment for AI infrastructure—an essential tool that arms developers and organizations with the capability to optimize their resources efficiently while fostering community-driven innovation. As the landscape of machine learning evolves, it becomes imperative for teams to adopt and adapt to these revolutionary tools that promise not just immediate returns but long-term advancements in the field.
Leave a Reply